概述
Pandas库在 NumPy的基础上,补充了很多对数据处理特别有用的功能,如标签索引、分层索引、数据对齐、合并数据集合、处理丢失数据等。因此,Pandas库已经成为Python 中执行高级数据处理的事实标准库,尤其适用于统计应用分析。
一些其他的相关库
statemodels,pasty,scikit-learn:更复杂的统计分析和建模Seabron:强大的统计绘图功能
Pandas中的两大主要数据结构:
Series和DataFrame
导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- 使用一种更美观的绘图样式
import matplotlib as mpl
mpl.style.use('ggplot')
- 导入
seaborn模块
import seaborn as sns
Series对象
基础操作
index,value属性- 与numpy的数组很像
s = pd.Series([98790, 234,57562, 6736])
print(s)
print(s.index)
print(s.values)
- 输出
0 98790
1 234
2 57562
3 6736
dtype: int64
RangeIndex(start=0, stop=4, step=1)
[98790 234 57562 6736]
更具有描述性的方式
- 可以把一个新的索引列表赋值给Series对象的index属性,也可以给 Series 对象的 name 属性设置有意义的名称。
s.index = {"北京", "上海", "广州", "深圳"}
s.name = "评分"
print(s)
print(s.index)
print(s.values)
- 输出
北京 98790
广州 234
上海 57562
深圳 6736
Name: 评分, dtype: int64
Index(['北京', '广州', '上海', '深圳'], dtype='object')
[98790 234 57562 6736]
- 也可以在创建Series的时候就设置索引和名称
s = pd.Series([98790, 234,57562, 6736], name="评分",
index = ['北京', '广州', '上海', '深圳'])
- 可以通过将索引作为下标来访问数据,也可以直接访问与索引名同名的属性
s['北京']
s.北京
- 使用一个索引列表来访问 Series 对象,将返回一个新的包含原始数据子集(与列表的索引对应)的 Series 对象
s[["北京", "上海"]]
获得Series的统计信息的方法
s.median()
s.mean()
s.std()
s.min()
s.max()
s.quantile()
- 以上所有信息都可以通过
describe()方法统一输出
print(s.describe())
count 4.000000
mean 40830.500000
std 46367.220731
min 234.000000
25% 5110.500000
50% 32149.000000
75% 67869.000000
max 98790.000000
Name: 评分, dtype: float64
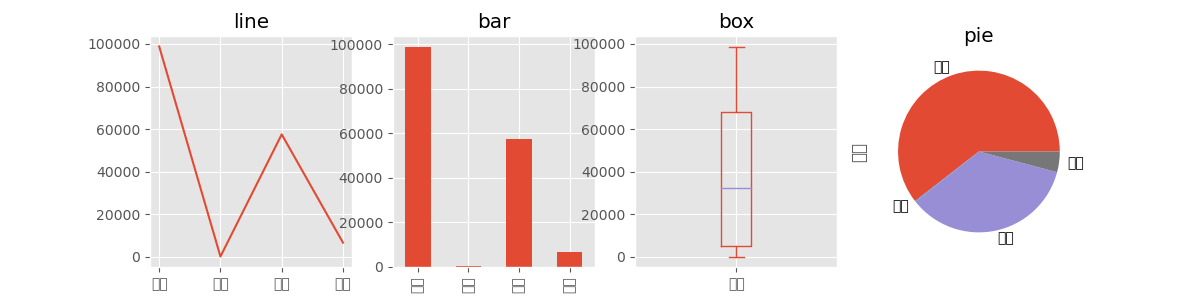
和matplotlib联动进行可视化
- 可以通过 ax 参数把一个 matplotlib Axes 实例传给 plot 方法
- 通过 kind 参数进行设置(可选值有 line、hist、bar、barh、box、kde、density、area 和 pie)
fig, axes = plt.subplots(1,4,figsize=(12,3))
s.plot(ax=axes[0], kind='line', title='line')
s.plot(ax=axes[1], kind='bar', title='bar')
s.plot(ax=axes[2], kind='box', title='box')
s.plot(ax=axes[3], kind='pie', title='pie')
plt.show()
DataFrame对象
DataFrame的初始化
使用嵌套列表
df = pd.DataFrame([[9999,"永州"],[8888,"成都"],[5555,"北京"],[1111,"上[>print(df)
0 1
0 9999 永州
1 8888 成都
2 5555 北京
3 1111 上海
- 可以通过index设置行索引,通过columns属性来设置列标签
df.columns = ['评分', '城市']
print(df)
评分 城市
0 9999 永州
1 8888 成都
2 5555 北京
3 1111 上海
使用字典进行初始化
- 列头是字典的键,每列的数据是字典的值
索引
类似于 NumPy 数组使用 values 属性获取数据一样,可以使用 index 和 columns 属性分别获取DataFrame 中数据的索引和所有列,其中的每一列可以使用与列名相同的属性来访。
df["评分"]和df.评分类似
loc索引器
从 DataFrame 中提取一列数据后,将返回一个新的 Series 对象。DataFrame 实例的行可以使用loc索引器属性进行索引。在该属性上进行索引后返回的也是一个 Series 对象,对应原始数据结构中的一行数据:
df.loc[0]
给loc索引器属性传入一个行标签列表后,将返回一个新的 DataFrame,它是原始 DataFrame 的一个子集,里面只包含选择的行。
df.set_index():将索引设置为其他的列
df_pop2 = df_pop.set_index("City")
sort_index():将索引作为关键字对所有数据进行排序
sort_values():根据某列进行排序,关键字ascending设置降序/升序
分层/多层索引
暂时略
统计信息
- 基本统计信息的获取:与Series类似,当调用相关的函数时,DataFrame会对每个数值类型的列进行计算
df.info()方法查看数据集的概要信息- 对于很大的数据集使用
df.head(),df.tail()截取首尾的子集
df.value_counts():对于分类数据进行统计
DataFrame读写数据
CSV文件
read_csv()函数:从.csv文件读取数据并创建DataFrame实例
- 可选参数 参数|作用 ---|--- header| 指定哪一行是列头 skiprows| 跳过开头的几行 delimiter| 每列之间的分隔符 nrows|
待添加
数据转换操作
df.apply()方法
- 把函数传给某列的 apply 方法之后,该函数将作用于该列中的每个元素,生成一个新的 Series 对象并返回。
- 例如,可以传递一个lambda 函数(用于去掉字符串中的“,”字符,并把结果转换为整数类型)给 apply方法,把Population 列的元素从字符串类型转换为整数类型。然后把转换后得到的列赋值给名为NumericPopulation的新列。
- 使用同样的方法,可以对 State 列中的数据进行清洗,再使用 stip 方法去除 State 列中每个元素末尾的空格。
df_pop[“NumericPopulation”] = df_pop.Population.apply(
lambda x: int(x.replace(',', ''))
)
df_pop["State"] = df_pop["State"].apply(lambda x: x.strip())